













Le Rize+ : informations internes
La vie du Rize+ : une mémoire collective évolutive
Le projet du Rize+ se situe dans la continuité du projet du Rize, dont trois objectifs importants sont de :
- rendre la culture, dans toutes ses acceptions, accessible à tous ;
- participer à la construction d’une histoire du territoire villeurbannais (par la collecte et conservation d’archives relatives au territoire, l’étude par des chercheurs de ces archives et leur valorisation auprès du grand public par des médiations) ;
- récolter, conserver, partager et faire vivre les mémoires villeurbannaises.
Ce site web permet à n’importe quel usager ou agent de se renseigner sur l’histoire de Villeurbanne et sur les mémoires qui lui sont associées : il peut accéder à de nombreuses archives numérisées des fonds conservés au Rize, mais aussi à des traces en ligne de médiations proposées au Rize au fil du temps.
À travers le Rize+, les anciennes actions du Rize peuvent ainsi avoir une seconde vie : elles survivent ainsi au temps court de l’évènement, se constituant au fil du temps comme traces des regards portés par des habitants, des artistes, des chercheurs et des médiateurs sur le territoire villeurbannais. Le Rize + participe ainsi à la constitution d’une mémoire de Villeurbanne, mais aussi d’une culture locale.
Il ne s’agit donc pas de donner accès à une actualité immédiate, mais d’offrir un voyage dans l’histoire et les mémoires locales. L’accès aux cultures (légitimes et populaires) s’ancre ainsi dans le temps long, participant ainsi à la continuité et à l’évolution d’une culture (au sens anthropologique) spécifiquement villeurbannaise.
Sommaire
Astuces Avenio
Quelques astuces pour utiliser Avenio, récoltées au fil du temps.
Exporter l'ensemble des inventaires XML-EAD
La procédure générale est décrite dans le Manuel Avenio à la page Généralités/les editions.
Ci-dessous les détails des opérations en copies d'écran.










Supprimer les retours chariots dans un champ dans Avenio
La procédure générale est décrite dans le Manuel Avenio à la page Annexes/Le mode expert.
Formule pour remplacer les retours chariot dans un champ.
Il faut le faire en mode Expert sur une sélection de fiches, depuis la table souhaitée.
Par exemple, dans le champ analyse des articles, on remplace chaque retour chariot par espace, tiret, espace.
[Articles]Analyse:=remplacer chaine([Articles]Analyse;caractere(retour chariot);" - ")

Astuces Rize+
Quelques astuces pour utiliser le Rize+, en attendant un tutoriel...
Imprimer joliment une page du Rize+
Pour que le document soit plus propre, cliquer sur "plus de paramètres" :

- Cocher l'option "imprimer les arrières plans" > le logo du Rize apparaît.
- Décocher l'option "Imprimer les en-têtes et pieds de page" > les marges du document sont propres.

Les enjeux de l'indexation
Le Rize est largement touché par les enjeux de description à la fois documentaires, archivistiques et patrimoniaux :
- mise en place d'inventaires territoriaux variés, s'inspirant notamment de ce qui est fait par l'Inventaire général du patrimoine culturel ;
- développement du Rize+, qui suppose une indexation pour que les internautes puissent facilement avoir accès à l'information ;
- politique nationale de "transition bibliographique" pour les bibliothèques (mise en relation des métadonnées des bibliothèques avec le web sémantique), portée notamment par la Bnf et Sudoc (et expliquée sur un site dédié).
- politique nationale (moins rapide) d'évolution des descriptions archivistiques vers la norme Ric. Voir par exemple la journée organisée par France Archives en 2020 : "les métadonnées archivistiques en transition", dont la synthèse est conservée sur le blog hypothèses des Archives Nationales.
Si ce contexte peut bousculer le fonctionnement actuel de certains services, il y a de fortes chances que, d'une manière ou d'une autre, il s'impose aux collectivités, via des instructions nationales.
Les politiques de métadonnées au sein des administrations nationales
D'une façon générale, les données produites par les administrations évoluent pour faciliter leur utilisation dans le contexte du web, mais aussi pour permettre de mutualiser les données entre différents services, différentes branches de la fonction publique.
A titre d'exemples, les données fiscales de la DGFip, les données de l'Insee et celles de l'Ign sont en phase d'harmonisation et viennent alimenter les analyses relatives aux territoires. L'harmonisation se déploie à plusieurs échelles : d'une part, en lien avec les institutions européennes, d'autre part, en lien avec les collectivités. Le Grand Lyon intègre par exemple certaines de ces données harmonisées (données économiques, données fiscales, ...), mais contribue aussi à les alimenter (données d'adresses, données cadastrales, ...). Les adresses et les parcelles cadastrales sont un terrain d'expérimentation et d'échanges importants entre les différentes administrations.
Autre exemple : la Note d’information DGP/SIAF/2012/015 en date du 12 novembre 2012, signée du directeur chargé des archives de France, détaille les évolutions récentes du Thesaurus pour la description et l'indexation des archives locales, mordernes et contemporaines. La mise à jour de ce Thesaurus s'inscrit dans un projet d'harmonisation des données culturelles au sein du ministère de la Culture. Ce projet "HADOC", est piloté par la Direction générale des patrimoines (DGPat).
En voici l'objectif annoncé :
"L’objectif est de créer un référentiel terminologique unifié permettant d’offrir aux usagers un accès unique et cohérent aux ressources terminologiques produites par le MCC et d’en démultiplier les usages."
En parallèle, La Bnf projette de mutualiser ses metadonnées avec Abes (Sudoc/MESRI), et avec d'autres organisations internationales, dans un Fichier national d'entités (FNE). Un prototype a aussi été élaboré par les institutions nationales d'archives (Archives Nationales, France archives, SIAF) pour expérimenter la potentielle mutualisation de métadonnées avec la BnF, via le web.
L'ensemble du processus d'harmonisation des données s'inscrit dans la stratégie d'Open Data de l'État, pilotée via sa mission Etalab, qui vient d'avoir 10 ans.
Un changement de modèle dans la description documentaire et administrative
L'évolution globale dans les différentes administrations et dans les établissements publics est le passage vers la description d'objets divers (ouvrages, oeuvres, documents d'archives, objets réels, entreprises réelles) grâce à des modèles "entités-relations", plus souples que ceux qui existaient auparavant, plus compatibles avec la recherche sur la web et plus interopérables.
Les organismes publics sont aussi de plus en plus incités à développer des Api (des "interface de programmation d’application" soit des plateformes permettant des échanges de données entre sites web). Ainsi, chacun peut récupérer les données de l'autre.
Adapter le modèle de données du Rize+ : vers une approche "entité-relations"
Pour faciliter la recherche d'information, Le Rize+ devrait, lui aussi, évoluer vers un modèle "entités-relations" : des listes d'adresses, de personnes, d'organismes, de lieux, communes à l'ensemble du site internet et permettant d'indexer l'ensemble des documents qui y figurent. Cette approche devrait permettre de mettre en place un moteur de recherche transversal à l'ensemble du site.
En cela, il se rapprochera du logiciel Avenio, utilisé par le pôle archives du Rize, qui fonctionne déjà selon un modèle de ce type. Il est donc souhaitable que les listes d'autorité et les index du Rize+ s'alignent ceux utilisés dans Avenio.
Prendre en compte les évolutions des normes archivistiques
Les listes d'autorité et index d'Avenio ont besoin d'un nettoyage, ainsi que de la rédaction d'un mode d'emploi. En effet, c'est leur qualité qui permet d'améliorer la recherche sur Avenio, et donc l'accès à l'information archivistique.
Pour éviter de faire le travail plusieurs fois, il est important de s'appuyer sur les normes archivistiques nationales (ISAD (G), ISAAR (CPF), ISDF, ISDIAH), les schémas d'informatisation de la description (DTD EAD, EAC-CPF), les circulaires, et nomenclatures (Géonomenclature historique des lieux habités, décembre 2003, Thésaurus pour la description et l'indexation des archives locales) déjà existants.
Mais, il est aussi stratégique de prendre en compte les évolutions en cours de ces normes (Standards du Web de données, norme Rico-O), pour éviter que ce travail de nettoyage des index ne devienne rapidement obsolète.

Les évolutions à prévoir pour les bibliothèques : la transition bibliographique
Par ailleurs, il y a de fortes chances que les descriptions bibliographiques des médiathèques municipales évoluent vers des modèles "entités-relation" puisque c'est la politique menée à l'échelle nationale.
A titre d'exemple, l'Abes et la Bnf projettent ensemble une plateforme commune dont l'objet rejoint la plupart des activités documentaires du Rize :
"Le Fichier national d’entités (FNE), co-réalisé par la BnF et l’Abes, est un projet de plate-forme centralisée de production mutualisée des données relatives à plusieurs des entités nécessaires à la description d’objets documentaires des bibliothèques, centres de documentation et potentiellement archives et institutions culturelles françaises."
Source : https://www.transition-bibliographique.fr/fne/charte-fichier-national-entites/Autre exemple : le CNFPT commence à sensibiliser les collectivités aux enjeux de la transition bibliographique, via des journées professionnelles dédiées.

Vers une meilleure transversalité des métadonnées documentaires au sein du Rize
Pour le fonctionnement du Rize, l'enjeu global est de simplifier l'accès aux informations produites et conservées par le Rize. Mais, on le voit, s'y ajoute un deuxième enjeu : préparer les transitions documentaires qui s'annoncent via les initiatives nationales. Il est donc stratégique de fabriquer au fil du temps des index communs entre les pôles du Rize qui le peuvent, avec ces perspectives en arrière-plan.
Les archives étant soumises à une réglementation et à des contraintes plus strictes que le pôle recherche ou le pôle valorisation, c'est de leurs contraintes qu'il convient de partir pour harmoniser le reste.
Les bibliothèques sont soumises à d'autres normes documentaires, et suivent leur propre logique, mais il y a de forte chances que leurs modèles de données se rapprochent au fil du temps de ceux utilisés pour les archives. Il est donc intéressant d'intégrer dans la réflexion (sans forcément s'y soumettre) les normes documentaires en cours d'élaboration au sein du groupe de travail national sur la "transition bibliographique". Cette approche permet d'anticiper les futures contraintes qui s'appliqueront vraisemblablement aux bibliothèques, et de les prendre en compte, au moins en partie.
On peut ainsi espérer que les index retenus pour les pôles archives, valorisation et recherche seront assez proches de ceux qui s'imposeront dans les années qui viennent au sein des bibliothèques municipales.
Rize+ / archives / bibliothèque / inventaires : des catégories communes
Les différentes activités documentaires du Rize ont en commun de devoir décrire des objets (document de médiathèque, fond ou pièce d'archives, oeuvre, bâtiment, entité géographique) à travers un certain de nombre de catégories, dont la forme est harmonisée.
Certaines d'entre-elles sont communes, du moins au niveau conceptuel :
- Type d'objet
- Personne physique (agent individuel)
- Groupe ou personne morale ou organisme (agent collectif)
- Lieu
- Dates
Chacune de ces catégories demande parfois d'y ajouter des précisions. Exemples :
- Personne physique : profession, poste, activité, etc.
- Groupe ou personne morale ou organisme : statut juridique, activité, etc.
- Lieu : type de lieu (adresse, rue, etc.)
- Dates : type de date (date unique, intervalle entre dates extrêmes, périodes historiquesetc.), source de la date, certitude de la date, etc.
Par ailleurs, l'harmonisation suppose de trouver une forme commune (typographie, ordre des termes), qui facilite les recherches et évite les doublons.
Références externes
On peut observer plusieurs références extérieures qui peuvent alimenter la réflexion ; celles-ci dépendent des métiers et des organisations qui les produisent.
Bibliothèques
Dans les bibliothèques, il est propable que le Système de description actuel Rameau (assez complexe), évolue vers un système adapté du modèle IFLA LRM.
"Le modèle IFLA LRM (Library Reference Model / Modèle de référence pour les bibliothèques) a été publié par l’Ifla en 2017. Ce modèle conceptuel, offrant une représentation schématique de l’activité des bibliothèques, est orienté vers les besoins des utilisateurs. Il est conçu pour être facilement transposable dans les technologies du web.
À terme, les notices bibliographiques seront amenées à être remplacées par un réseau d’entités et de relations entre ces entités, qui seront plus visibles sur le web. Une voie est ouverte vers une interopérabilité accrue des données des catalogues de bibliothèques."
Source : https://www.transition-bibliographique.fr/enjeux/definition-ifla-lrm/
Archives
Dans les services d'archives, il est probable que les pratiques intègrent au fil du temps le modèle conceptuel RIC-CM, à travers les différentes versions de la norme RIC-O.
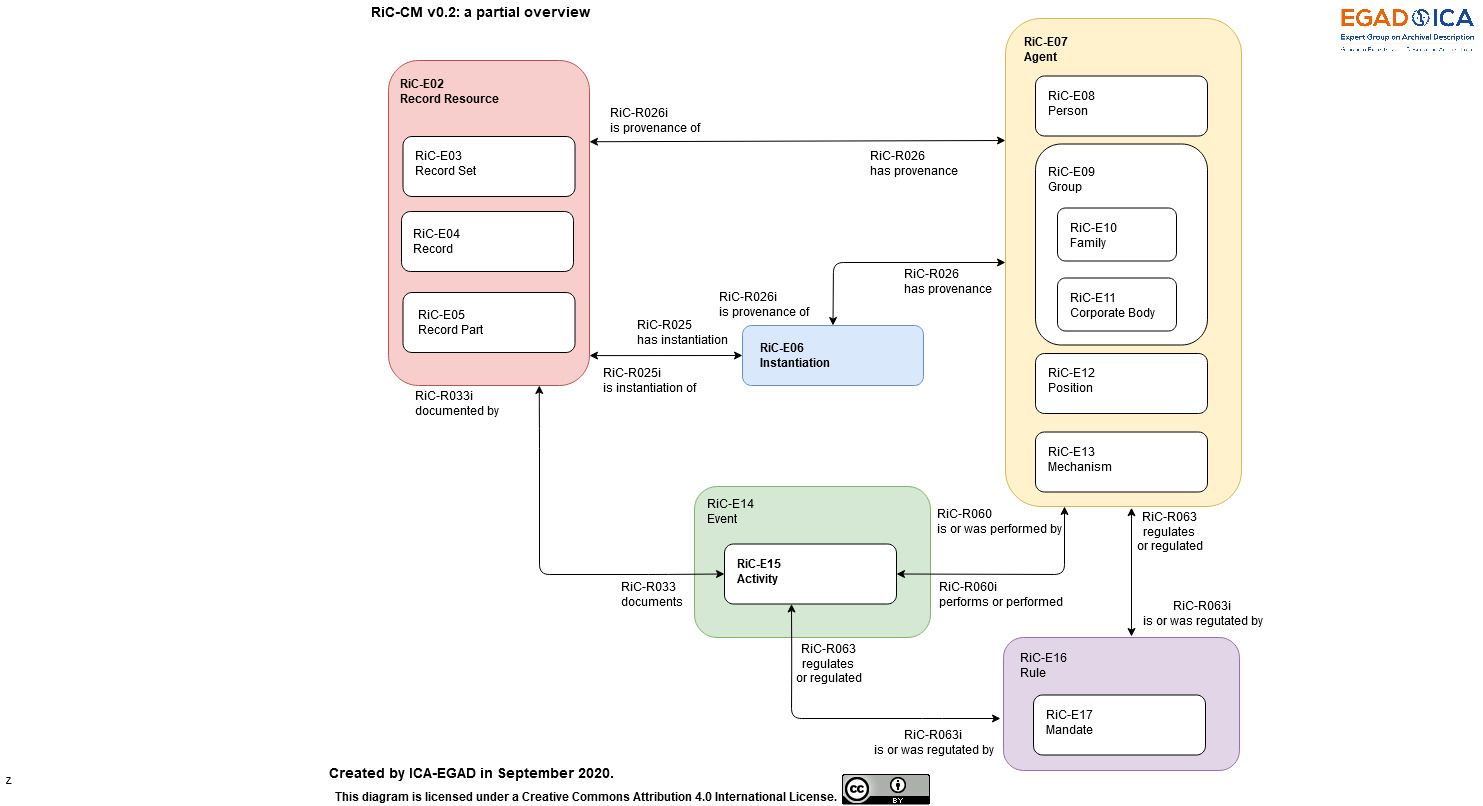
Ce modèle permet, par exemple de décrire :
- les relations entre une personne physique et une organisation

- un lieu

On le voit, cette modélisation du lieu permet de faire le lien entre la description dans un logiciel d'archives d'un lieu (ici, une commune) et sa définition pour des systèmes d'information géographiques (Ign, Géonames du W3C sur le web) ou des normes statistiques (Insee). Elle permet donc de faire concrètement le lien avec des données géographiques créés ou commandées par le Rize à travers ses inventaires géolocalisés (Carnet des mémoires, inventaire des noms de rue, inventaire professionnel du bâti).
Sources de données sur Villeurbanne
Cette rubrique répertorie au fil de l'eau des sources de données externes et internes sur Villeurbanne.
Exploiter l'inventaire professionel du patrimoine bâti
Exploiter les images
(mise à jour 21 mai 2021)
Pour chaque entrée de l'inventaire, plusieurs photographies ont été réalisées par les enquêteurs. Celle-ci ont été redressées par lot par le prestataire pour se rapprocher des codes des images de photographie architecturale.
A chaque fois, une "image significative" a été retenue. Les autres photographies visent à documenter le ou les édifices selon plusieurs angles, ou des détails importants.
Volume de données et stockage
Description
- 82469 images dont 7986 "images significatives"
- Dimension d'1 image : 3648px*5472px (vertical) ou 5472*3648 (horizontal)
- Poids d'1 image : entre 10 et 20 Mo par image selon les cas
- Volume total : plus de 800 Go (à préciser)
Enjeux techniques initiaux
- Gestion archivistique des images originales
- Mode de conservation actuel : sur disque dur indexé à la cote 373W et conservé dans un magasin d'archives. Conservation non pérenne.
- Nécessité de stocker ce données sur un serveur, avec back-up
- Pas d'indexation des images à ce jour. Elles sont simplement reliées à une entrée dans la base de données de l'inventaire.
- > A faire, par lots, dans la table "Illustrations" de la base de données ?
- > tagger les images dans les données EXIF/XMP de l'image (logiciel ExiftoolGUI ou JeExifToolGUI) ?
- Exploitation sur le web des "images significatives"
- Trois usages repérés : WebSig de la ville, mise en ligne de l'inventaire sur le Rize+, utilisation pour envoi sur les réseau sociaux du Rize (Instagram, Facebook; la référence prise est Instagram)
- Dimensions des images web à définir
- Process pour extraction des "images significatives" et redimensionnement pour le web à définir
- Définir un serveur pour stockage des "images significatives web"
process de traitement
Process de stockage des images originales
- Choix et mise en place d'un espace sur serveur dédié
- Transfert des images du disque dur sur le serveur
- Fourniture du chemin du dossier sur le serveur aux personnes en charge d'exploiter les images pour le web
Process d'extraction des "images significatives"
- Qgis > Table "sysLinks.xls"
- Jointure avec la table "Illustration.xls"
- Import des colonnes SENS (valeurs : H pour horizontal et V pour vertical) et FNU (valeur : nom_du_fichier_image.JPG).
- Préfixe de jointure : ILLU_
- Excell > Table "sysLinks_jointure.xls"
- Créer colonne CHEMIN et y coller le chemin du dossier de stockage des images originales
- CONCATENER colonnes CHEMIN et ILLU_FNU > colonne CHEMINFICH
- Filtre "images significatives" : colonne MARQ (valeur : 1) ou TLIEN (valeur "images significatives)
- Copier et coller l'ensemble des colonnes dans nouveau fichier : "sysLinks_joint_img_sign.xls"
- Excell > Table "sysLinks_joint_img_sign.xls"
- Filtre pour sens d'images : colonne SENS (valeurs : "h" pour horizontal et "v" pour vertical)
- Copier l'ensemble des lignes de CHEMINFICH pour SENS=H
- Coller dans fichier IMG_SIGNIFICATIV_H.txt
- Copier l'ensemble des lignes de CHEMINFICH pour SENS=V
- Coller dans fichier IMG_SIGNIFICATIV_V.txt
- Commande DOS pour copier les images significatives dans deux dossiers (chemins des dossiers à modifier le cas échéant)
- FOR /F "delims=" %t IN (C:\Users\abo\Documents\test\IMG_SIGNIFICATIV_H.txt) DO copy "%t" "C:\Users\abo\Documents\test1H"
- FOR /F "delims=" %t IN (C:\Users\abo\Documents\test\IMG_SIGNIFICATIV_V.txt) DO copy "%t" "C:\Users\abo\Documents\test1V"
Dimensions actuelles d'images en ligne utilisées par le Rize
| Usage | Orientation | Larg. (px) | Haut.(px) |
|---|---|---|---|
| Instagram (post) | carré | 1080 | 1080 |
| Instagram (post) | horizontal | 1080 | 566 |
| Instagram (post) | verticale | 1080 | 1350 |
| Instagram (story) | verticale | 1080 | 1920 |
| Facebook (couverture) | horizontal | 851 | 315 |
| Facebook (post) | sans objet | 1920 | 1080 |
| Facebook (event) | horizontal | 1280 | 960 |
| Synthèse Instagram ou Facebook Rize | Vertical | 1080 | 1350 |
| Synthèse Instagram ou Facebook Rize | Horizontal | 1920 | 1080 |
| Rize+ : qualité moyenne (fomat page actuel) | Vertical | 900 | 1350 |
| Rize+ : qualité moyenne (fomat page actuel) | Horizontal | 900 | 600 |
| Site du Rize (carrousel de page d'accueil/actu) | horizontal | 960 | 320 |
| Site du Rize (publication format actuel) | sans objet | 960 | variable |
| Rize+ : vignettes | Vertical | 300 | 300 |
| Rize+ : vignettes | Horizontal | 300 | 300 |
Déterminer trois dimensions d'images utilisables sur un grand nombre de supports
| Usage | Version | Orientation | Larg. (px) | Haut. (px) | Résol. (dpi) | Larg. Max (cm) | Haut.max (cm) |
|---|---|---|---|---|---|---|---|
| Conservation archives +Impression pro 300 dpi |
Img originale V1 | Vertical | 3648 | 5472 | 300 | 26,47 | 39,71 |
| Conservation archives +Impression pro 300 dpi |
Img originale V1 | Horizontal | 5472 | 3648 | 300 | 39,71 | 26,47 |
| Réseaux sociaux +Consultation archives +Impression bureautique 180 dpi |
Img dégradée V2 | Vertical | 1080 | 1620 | 180 | 15,24 | 22,86 |
| Réseaux sociaux +Consultation archives +Impression bureautique 180 dpi |
Img dégradée V2 | Horizontal | 1920 | 1280 | 180 | 27,09 | 18,06 |
| Sites Rize et Rize+ | Img dégradée V3 | Vertical | 720 | 1080 | |||
| Sites Rize et Rize+ | Img dégradée V3 | Horizontal | 1080 | 720 |
Tester différents modes de redimensionnement et de compression
Comparaison Fotosizer/script Photoshop : rapport qualité/poids des images
| Logiciel | Param. Compress. | Vers. | Orient. | Larg. (px) | Haut. (px) | Poids moy. img (Mo) | Poids moy. img (%) | Avantages | Inconvénients |
|---|---|---|---|---|---|---|---|---|---|
| Fotosizer | 100% | Img V2 redim. | Vert. | 1080 | 1620 | 1,51 | 100,00% | Facilité d'usage Filtre lumière Qualité OK |
Trop lourd |
| Fotosizer | 100% | Img V2 redim. | Horiz. | 1920 | 1280 | 2,22 | 100,00% | Facilité d'usage Filtre lumière Qualité OK |
Trop lourd |
| Fotosizer | 100% | Img V3 redim. | Vert. | 720 | 1080 | 0,71 | 100,00% | Facilité d'usage Filtre lumière Qualité OK |
Trop lourd |
| Fotosizer | 100% | Img V3 redim. | Horiz. | 1080 | 720 | 0,78 | 100,00% | Facilité d'usage Filtre lumière Qualité OK |
Trop lourd |
| Fotosizer | 75% | Img V2 dégradée | Vert. | 1080 | 1620 | 0,38 | 25,17% | Facilité d'usage Filtre lumière Qualité OK |
Pas de jpeg progressif |
| Fotosizer | 75% | Img V2 dégradée | Horiz. | 1920 | 1280 | 0,56 | 25,06% | Facilité d'usage Filtre lumière Qualité OK |
Pas de jpeg progressif |
| Fotosizer | 75% | Img V3 dégradée | Vert. | 720 | 1080 | 0,20 | 28,26% | Facilité d'usage | Qualité moindre Pas de jpeg progressif |
| Fotosizer | 75% | Img V3 dégradée | Horiz. | 1080 | 720 | 0,21 | 28,00% | Facilité d'usage | Qualité moindre Pas de jpeg progressif |
| Photoshop | 7 | Img V2 dégradée | Vert. | 1080 | 1620 | 0,50 | 32,76% | Bicubique net +jpeg progressif =qualité sup |
Dispo logiciel Plus lourd Pas de filtre lumière |
| Photoshop | 7 | Img V2 dégradée | Horiz. | 1920 | 1280 | 0,59 | 26,55% | Bicubique net +jpeg progressif =qualité sup |
Dispo logiciel Plus lourd Pas de filtre lumière |
| Photoshop | 7 | Img V3 dégradée | Vert. | 720 | 1080 | 0,18 | 42,75% | Bicubique net +jpeg progressif +accentuation =qualité sup |
Dispo logiciel |
| Photoshop | 7 | Img V3 dégradée | Horiz. | 1080 | 720 | 0,28 | 36,47% | Bicubique net +jpeg progressif +accentuation =qualité sup |
Dispo logiciel |
Conclusion
Pour le redimensionnement de V1 à V2, Fotosizer est performant. L'ajout d'un filtre "lumière" permet d'améliorer l'aspect de l'image par temps gris. Par contre, un redimensionnement direct depuis l'image originale vers la V3 n'est pas concluant : de nombreux artefacts, manque de précision de l'image.
Pour le redimensionnement de V1 à V2, le script Photoshop n'est pas le plus performant. Par contre, l'approche par redimensionnements successifs, avec un filtre "accentuation" amène une meilleur qualité d'image pour la V3 :
- on ne prend pas comme source l'image originale (V1), mais l'image dégradée V2;
- un filtre "accentuation" est appliqué sur l'image avant et après le redimensionnement (renforcement de la précision de l'image)
- l'algorithme de redimensionnement choisi est "bicubique net" (adapté à la réduction d'images).
Par ailleurs, Photoshop permet l'enregistrement en "jpeg progressif" qui donne un temps de chargement inférieur sur une page web.
On pourrait donc effectuer un traitement en deux phases :
- redimensionnement de V1 à V2 avec Fotosizer (un filtre "lumière" pour les photographies prises à certaines périodes de l'année, quand le temps est gris; compression 75%);
- redimensionnement de V2 à V3 avec Photoshop (filtre "accentuation", redimensionnement en bicubique net, enregistrement en .jpeg progressif, qualité 8).
Cette démarche offrire le meilleur rapport qualité / poids de l'image pour l'usage en masse sur le Websig et le Rize+. Les images ci-dessous montrent le rendu final.


Estimer les espaces de stockage nécessaires pour les données redimensionnées
| Usage | Version | Orient. | Nb img. signif. | Estim (Mo) Poids moy. img | Estim (Mo) Poids tot. ss-dossier | Estim (Mo) Poids tot. dossier | Estim (Go) Poids tot. dossier | Serveur |
|---|---|---|---|---|---|---|---|---|
| Conservation archives + Impression pro 300 dpi |
Img V1 originale | Vert. | 1409 | Archivage données numériques |
||||
| Horiz. | 6577 | |||||||
| Réseaux sociaux + Consultation archives + Impress. bureau 180 dpi |
Img V2 dégradée | Vert. | 1409 | 2,69 Go | Rize courant | |||
| Horiz. | 6577 | |||||||
| Sites Rize et Rize+ + Websig |
Img V3 dégradée | Vert. | 1409 | 2Go | WebSig Ville; webRize; Rize+ |
|||
| Horiz. | 6577 |
A télécharger
Le détail des différents calculs de cette page au format .xls